Introduction
There has been a growing interest in knowledge graphs and how they can help improve LLMs performance by providing more contextual and understandable answers. Specifically in RAG based applications, companies such as Langchain and LlamaIndex are starting to move towards knowledge graph systems instead of vector databases.
I found this relatively new concept of knowledge graphs interesting and have therefore started to explore (1) how they work, (2) how they compare with vector databases and (3) what are some of the use cases for knowledge graphs in industry.
What Are Knowledge Graphs?
Knowledge graphs are another way to format text information in a structured way. Think of a table with rows and columns, where each row represents an item. For example a person named Joe and his features would be the row with the columns holding information about Joe, such as his age and height. With this table it is possible to create multiple entries for different people, for example a year 10 class of students.
 Figure 1: Tabular representation of students.
Figure 1: Tabular representation of students.
Knowledge graphs can also store this information about each student but slightly differently and with additional benefits. Each student and piece of information are nodes (represented by circles) and are joined by edges, showing connections or relationships between each other. With this approach there will be only 1 node that says the age 16 with multiple edges from different students connecting into it. This provides 2 main benefits, the first being decreased storage and the second being a more effective way to interpret the data.
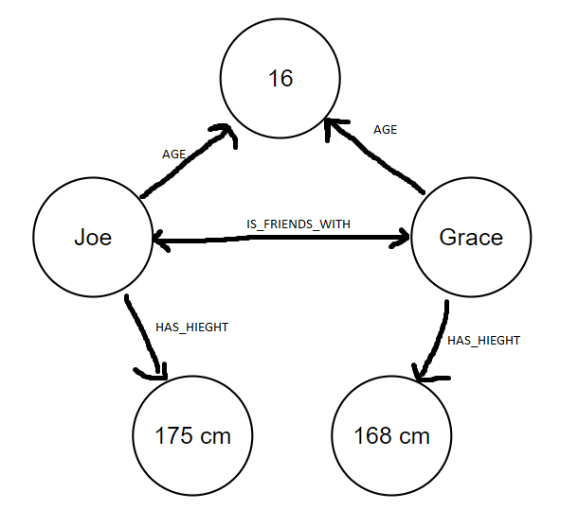 Figure 2: Knowledge graph representation of students.
Figure 2: Knowledge graph representation of students.
If we wanted to find out who in this class is of age 16 it would only take 1 pass for the knowledge graph to search for that information, however you would need to iterate over the entire table to check which students have this age. When scaling up to a big dataset this increase in inference is very beneficial. Another added benefit to storing information in knowledge graphs is for easily understanding relationships between different nodes, which tables struggle to do. For example, if we wanted to find out who is friends with whom, this can be represented by no additional nodes or entities but by simply adding an edge between 2 nodes with the label “IS_FRIENDS_WITH”. This method of relationships between entities, or nodes, is the most important part of knowledge graphs, being able to create vast networks of interconnected concepts.
Knowledge Graphs vs Vector Databases
The relationships between nodes in a knowledge graph allows for an in depth understanding of not only what concepts are semantically close but how they connect to each other. Let’s use a new example of a knowledge graph of concepts around Artificial Intelligence (AI) as seen in Figure 3. If we take 2 concepts, say image recognition and deep learning, we can find the chain that connects these together: image recognition → computer vision → artificial intelligence → deep learning. As we continue to grow these knowledge graphs, more interconnected nodes appear and more connections are made between concepts, allowing for a deeper contextual understanding of a concept compared to just agreeing that 2 concepts are semantically close.
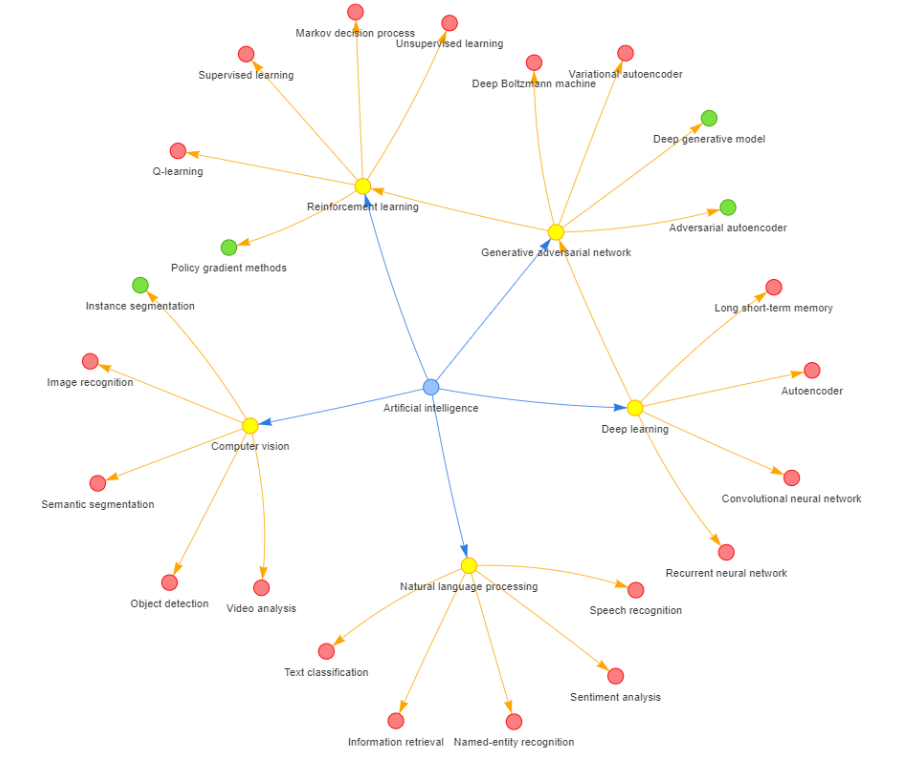 Figure 3: Knowledge graph of concepts around Artificial Intelligence.
Figure 3: Knowledge graph of concepts around Artificial Intelligence.
An interesting concept that is becoming increasingly popular is using knowledge graphs instead of or in addition to vector databases for retrieval augmented generation (RAG) applications. As discussed above, using knowledge graphs allows for a much more contextual meaning for concepts in natural language and can clearly map how concepts are interconnected which vector database RAG applications struggle to do.
The pipeline for finding a similar concept or document using a vector database RAG system would be as follows:
- Embed all documents/concepts
- Embed new document/concept (image recognition)
- Use a cosine similarity search to find the top k similar embeddings (usually 3-5)
- Return the text of found sources
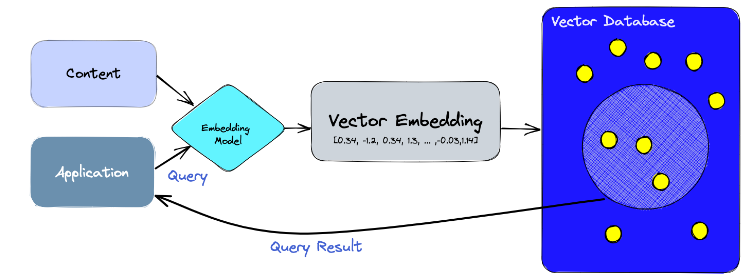 Figure 4: Pipeline for a RAG based application using a vector database.
Figure 4: Pipeline for a RAG based application using a vector database.
However there are a few problems with using a vector database for similarity searching:
Understandable Results: There is no understanding how it has chosen the similar documents or concepts, they can be and are usually very similar topics, however there is no contextual knowledge on its choice. It is not possible to be certain whether the vector database search has returned a relevant document or how it has made its decision and therefore it is difficult to trust the answers of an LLM system with a vector database. Even more, the process of a vector similarity search is simply comparing numbers (embeddings) to each other, and when we get a highly dense vector database with many similar documents it becomes difficult to differentiate between these sources allowing for more uncertainty in the return documents.
Set Number of Results: RAG with vector databases returns a set k number of sources whether there are any similarities at all or if there are more than the set value. Therefore this pipeline can either not give the LLM enough information to answer the question completely or we are providing the LLM with junk information, using up more tokens and slowing inference.
Evidently knowledge graphs solve these 2 issues of vector databases, achieving more understandable and accurate results. Concepts are easily connected together by following chains of nodes and edges which can be represented to create an understandable output to the user and LLM. Knowledge graphs are also not restricted to return a set number of results due to only returning all the information relevant to the query. For example if we wanted to find out what books an author has written our knowledge graph will return exactly the entire list however a vector database search will only find 5 books (given a set value of 5) before being cut off, failing to answer the question.
As mentioned earlier, knowledge graphs can be used in addition to vector databases. Using a vector database similarity search to find the most similar concept or document is very valuable at times and is very good at finding the most semantically similar document. Using a knowledge graph at this point in the pipeline can be more beneficial, to use this found document and explore what is contextually related to it can provide more accurate surrounding knowledge and increase the LLMs performance in answering a question. Another way is to compute both a vector search and a knowledge graph search for documents and re-rank the top found documents by a joint comparison.
Knowledge Graph Use Cases
Knowledge graphs are a new way of perceiving or storing information, specifically text based information and I believe will become fundamental due to the success in language models. LLMs allow for knowledge graphs to be more easily constructed and queried, which I will discuss in a future article. The biggest use case of knowledge graphs will be within LLM applications, integrating into RAG systems in conjunction with or replacing vector databases. These graphs are a great tool in information retrieval and question answering, showing improvement in LLM tasks due to its contextual understanding and entity linking.
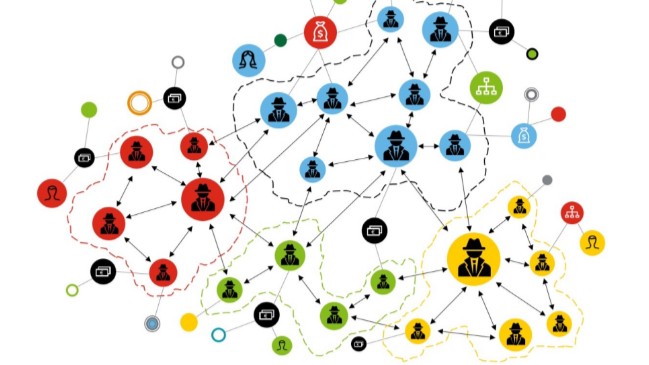 Figure 5: Knowledge graph of a team.
Figure 5: Knowledge graph of a team.
Vector databases are not useless and will more than often be sufficient enough for RAG applications, however here are multiple examples where knowledge graphs can play an integral role, besides a vast improvement in chat bot applications.
Healthcare: Model relationships between patients, medication and medical conditions to create an intelligent system to retrieve relevant patient information and hospital wide statistics.
E-commerce: Model relationships between different products and user purchases to help identify which products to recommend to users based on contextual similarities.
Legal: Represent relationships between legal cases, entities, statutes, and precedents in helping understand the complexities of the data with contextual information finding.
Team Organisation: Model people as nodes connected by skills, relations, qualification, and other concepts to aid in identifying the correct people for tasks or opportunities. For example choosing which person to hire based on resumes or which employee to lead a new task.
From these few examples it is evident that knowledge graphs are best used in situations where relational connections are necessary such as between people, products or complex information.
Conclusion
The change from vector databases to knowledge graphs shows real promise in advancing LLMs, especially in RAG applications. Knowledge graphs allow for more interpretable and comprehensive results, addressing the limitations of vector databases in contextual knowledge and set number of sources returned.
With the continual improvement in language models, knowledge graphs will continue to show more value in structuring and querying data, finding use cases in multiple industries ranging from healthcare, e-commerce, legal, team management and many more.