
Introduction
Last article I described what knowledge graphs are at a high level, how they fundamentally work, and outlined a few industry use cases. One of the use cases covered was team organisation which modelled people, their skills, education, etc into a knowledge graph for tasks such as identifying correct people/employees for opportunities. A great example of this would be for an organisation choosing a person to hire based on hundreds or thousands of resumes.
This article will work through how to build a knowledge graph using large language models (LLMs) with this example of resumes.
Creating a Knowledge Graph
Constructing a knowledge graph is completed in 6 main steps:
- Data Preparation
- Coreference Resolution (optional)
- Entity Extraction
- Relationship Extraction
- Entity Disambiguation
- Graph Construction This explanation will focus on how to use these 6 steps to create a knowledge graph from resumes, however these steps present a general framework for creating a knowledge graph with any form of text data and can therefore be used in multiple different situations.
1.Data Preparation
The first step in creating a knowledge graph is making sure your data is in a clean and structured format. This step is usually ignored by many developers, jumping straight into working with the data, however making sure your data is clean and structured well makes a big positive impact.
LLMs are very good at handling all types of unstructured data, however with knowledge graphs it is good to avoid outliers and therefore removing documents or data from the dataset that are not relevant will increase the performance. In the resume example, having a few cover letters in the dataset will create confusion for the model and therefore should be removed.
Preparing the data in an ingestible format is also important, making sure you have correctly extracted the raw text data from the documents you are working with. For the resumes the dataset could consist of a variety of pdfs or word documents and therefore the raw text must be extracted and stored in all the same format, for example in a txt file.
2.Coreference Resolution (optional)
Another crucial step in data preparation for knowledge graphs is coreference resolution, however this is not necessary in all tasks, but will play an important role with a resume dataset. Therefore I have separated this as an optional step in the knowledge graph creation pipeline.
Coreference resolution is finding all entities or pronouns that refer to the same thing and relabelling them.
For example take this sentence:
“John told Sally that she should come watch him play the violin.”
“John” and “him” refer to the same entity, same as “Sally” and “she”. By resolving these coreferences the LLM or other entity extraction techniques are able to more easily and accurately extract useful information for the knowledge graph.
3.Entity Extraction
One of the most important steps in the knowledge graph creation process is extracting the entities. Entities are represented by the nodes of the knowledge graph and will be filled with succinct pieces of information gathered from the data sources. With resumes the entities to extract would be the name, skills, education, employment position and company. See Figure 2 for the high level structure of the knowledge graph for a single resume extraction.
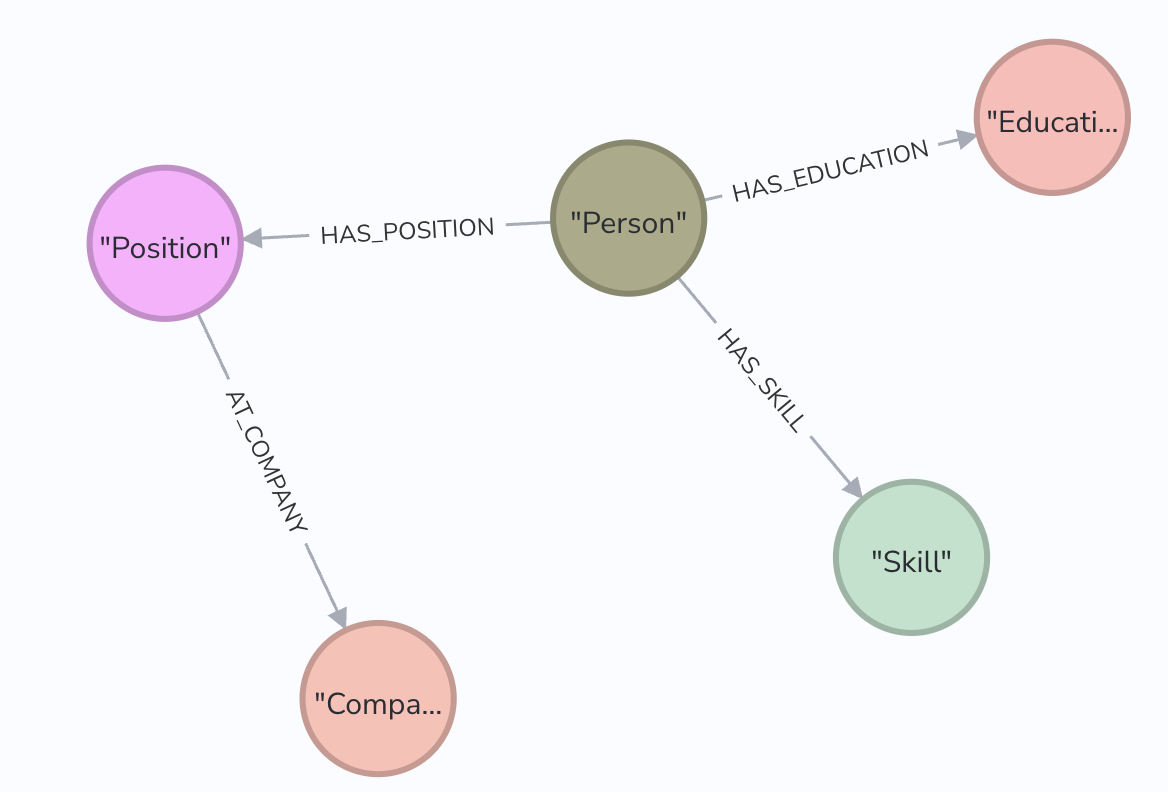 Figure 1: High level knowledge graph structure for a resume.
Figure 1: High level knowledge graph structure for a resume.
There are 2 ways to extract entities, first using more basic natural language processing (NLP) techniques such as NER and second using the famous LLMs.
NER: NER stands for Named Entity Recognition and is in simple terms a trained NLP model to identify entities such as people, locations, dates, etc. from a text input. An example of a NER model is the BERT-NER which can be simply implemented in python using the following github: https://github.com/kamalkraj/BERT-NER
LLMs: The second technique for entity extraction is to use an LLM with careful prompting. With the impressive improvements in LLM models, especially using GPT with the JSON output mode is very effective in returning a structured format of the entities.
We can pass a document to an LLM and prompt it to extract certain entities of information and return it in a structured JSON output for simple use. To increase accuracy you can create an individual prompt for each entity you want to extract, however this does come at an increase in cost and time.
This approach has become more prevalent, overtaking NER models as they are more generalisable and easier to implement.
4.Relationship Extraction
The next step in creating a knowledge graph is to use the extracted entities and link them together with relationships. A relationship is represented by the edges of the graph, creating connections between entities.
With resumes it is a fairly simple process and can be easily structured. We extract the entities from a person's resume as seen in Figure 2 and can map the relationships as “HAS_EDUCATION”, “HAS_SKILL”, etc.
This is a very basic approach as we have an understanding of exactly what relationships and entities we want to extract. A more advanced method is to use an LLM to do both the entity and relationship extraction at the same time. In short, you pass a sentence, or chunk, to the LLM one at a time and prompt it to find any entities and relationships in the given text. As seen in Figure 3 the unstructured text data is passed to the LLM which in turn will return a structured knowledge graph entry with the entities and relationships. This allows for a more generalisable knowledge graph creation and can be very useful in many situations.
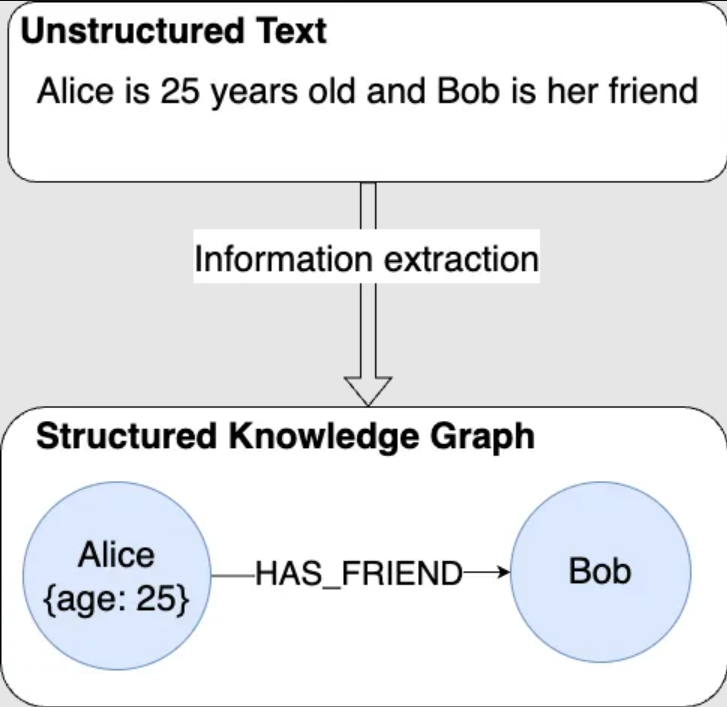 Figure 2: Generalised entity and relationship extraction using an LLM.
Figure 2: Generalised entity and relationship extraction using an LLM.
5.Entity Disambiguation
One of the biggest challenges with using LLMs to create knowledge graphs is the duplication of entities. For example with the education entities in a resume knowledge graph there can be 2 entities: “Curtin” and “Curtin University”. These 2 entities represent the exact same thing but are separate nodes in the graph, and hence there needs to be a deduplication.
Deduplication, known as entity disambiguation, can be completed by employing an LLM once again. Firstly we organise the entities based on their types, for example put all the education entities together. We then provide the LLM with these sets of entities and with careful prompting we can get the model to remove duplicated entities, creating a much more structured and cleaner knowledge graph.
Older and more traditional NLP models exist for this task as well, such as ExtEnD https://github.com/SapienzaNLP/extend, however these methods have been superseded by LLMs.
6.Graph Construction
The last step in creating a knowledge graph is putting all the structured and extracted data into a graph for easy visualisation.
The best graph visualisation tool in the market is Neo4j: https://neo4j.com/
This process is straightforward, writing a bit of code to transform your extracted data into a format compatible with the Neo4j importer tool which uses Cypher language.
The end result will look something like Figure 4, being able to easily view the extracted data for a single resume. You would also load all the resumes into a single knowledge graph and can therefore find overlaps of entities, being able to identify all the people who have a certain skill or education efficiently.
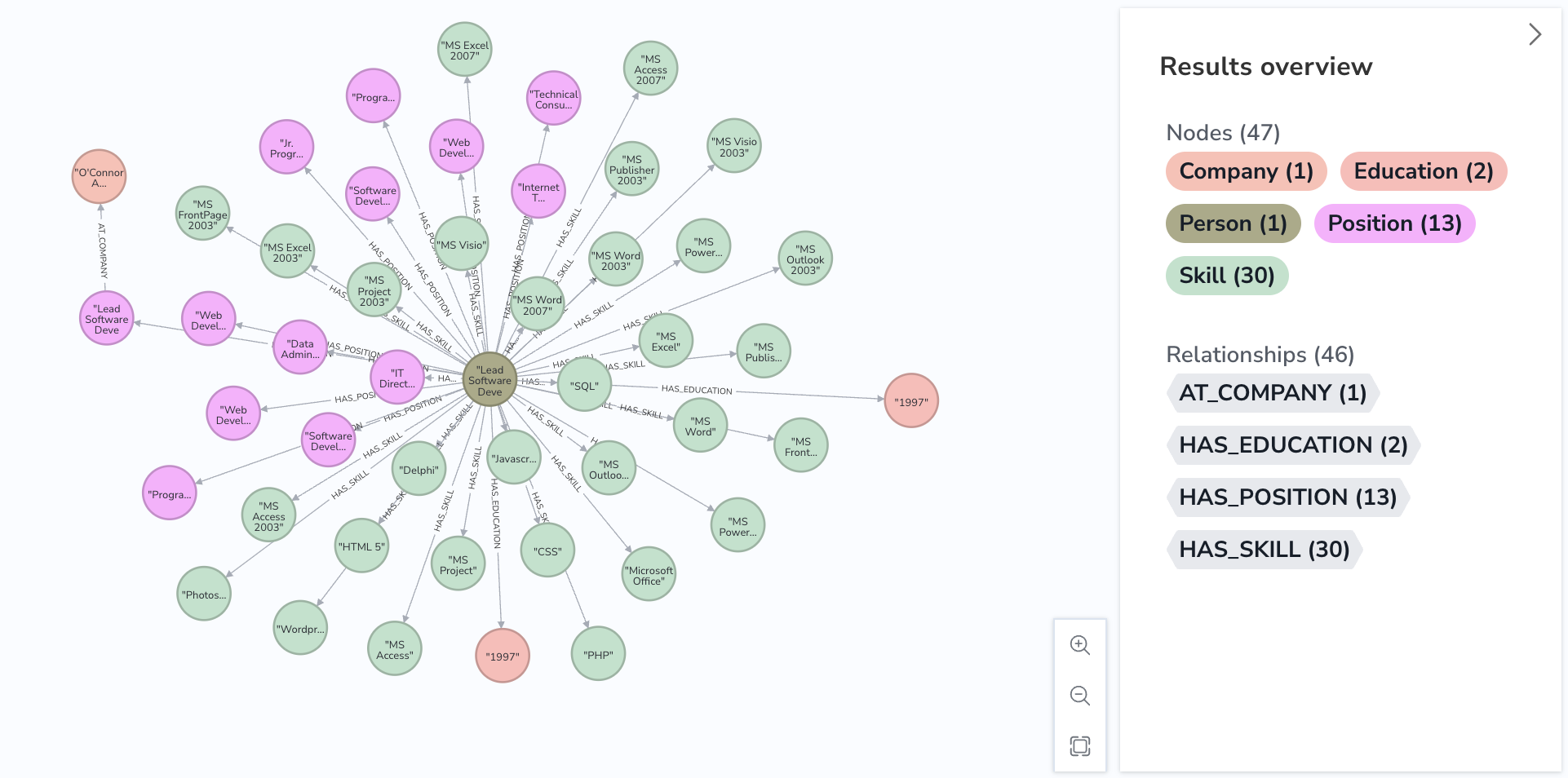 Figure 3: Knowledge graph visualisation using Neo4j for a single resume.
Figure 3: Knowledge graph visualisation using Neo4j for a single resume.
Conclusion
Constructing a knowledge graph has become a much easier process with the large improvements with LLMs, allowing for many useful applications to be built. This article explored building out a knowledge graph for a set of resumes, showing how this can be made to allow an employer to quickly and easily find information from a large number of entries, such as who has certain skills, levels of education, or x amount of experience in previous jobs.
Knowledge graph construction is a logical 6 step process from data preprocessing to extracting the information using LLMs and constructing and visualising the graph using Neo4j. To further improve the readability of knowledge graphs and to use their structured and relational format to answer questions it is possible to use them in RAG based applications, which I will explore in a future article.